Vector Database That Scales
The scalability of a vector database in the context of massive AI data is of paramount significance.
As AI applications increasingly rely on large datasets for training and inference, the ability of a
vector database to seamlessly scale to handle vast amounts of data becomes a critical factor.
AI technology is orchestrating a profound revolution in both business and daily life. The transformative
impact of AI is reshaping industries, enhancing efficiency, and redefining how we interact with technology.
As data volumes grow exponentially, a scalable vector database can handle the influx of information
without compromising performance. Horizontal scaling involves adding capacity to accommodate the
accelerated growth of AI data. It is a top priority when selecting a vector database.
However, traditional methods of horizontal scaling involve moving large
amounts of data among computer servers, which is slow and risky. This process is often considered the
horrifying nightmare of distributed data systems. JaguarDB has overcome this challenge with its innovative
ZeroMove technology, which allows a database cluster to scale horizontally instantly to any size,
eliminating the need for data migration and significantly improving scalability and performance.
This article describes our revolutionary technology of scaling-out distributed database systems:
Techrxiv PDF Document: Zero Data Migration
|
AI Data Infrastructure
Embeddings vectors carry semantic meaning and intelligence in various fields of artificial intelligence, including natural language processing (NLP) and computer vision. These vectors are representations of data, such as words, phrases, or images, in a continuous and dense vector space. They are designed in a way that similar items in the original data are represented as vectors that are close to each other in the vector space. JaguarDB, powered by its innovative ZeroMove technology, offers unparalleled scalability for
handling big data in AI learning. With its advanced AI datalake and data warehouse infrastructure, JaguarDB efficiently
accommodates the demand for answers and consistently delivers impressive results. Leveraging its
robust capabilities, JaguarDB empowers users with powerful search functionalities to
extract valuable AI insights from massive volumes of data.
How ZeroMove Works
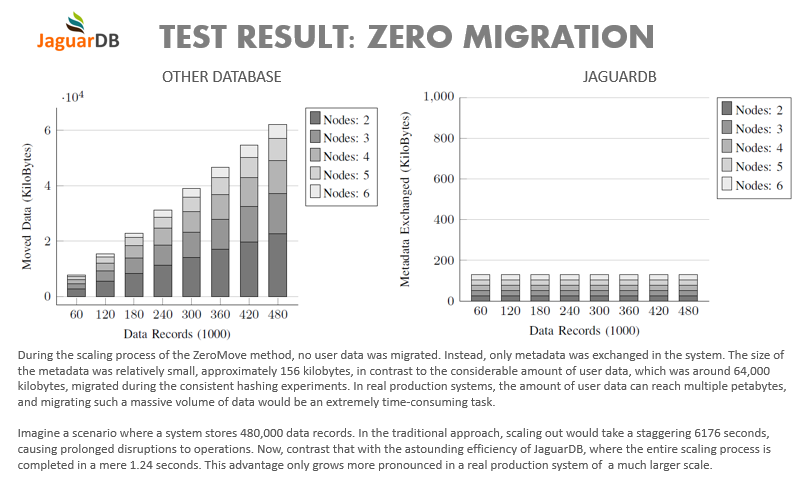
In the traditional consistent hashing mechanism, adding nodes can still lead to significant data movements.
In a distributed system utilizing consistent hashing, the majority of data records created and stored within
the system will experience migration from one node to another. This migration occurs as a result of a sequence
of incremental scaling processes that the system undergoes. This excessive data migration results in high costs for the system,
including increased power consumption, hardware wear and tear, and degraded performance. ZeroMove hashing protocol is a
method of distributing data to nodes arranged in clusters. Unlike other
hashing protocols, ZeroMove hashing does not require data to be moved from one node to another
during a scaling process. Rather, data remains in the node where it was originally hashed indefinitely.
This approach ensures that data remains in the node where it is hashed, thereby increasing
availability and improving system performance. Furthermore, the ZeroMove hashing technique
can significantly reduce facility and administrative expenses, making it an excellent option
for large-scale distributed systems.
Click Here For Video Demonstration of ZeroMove
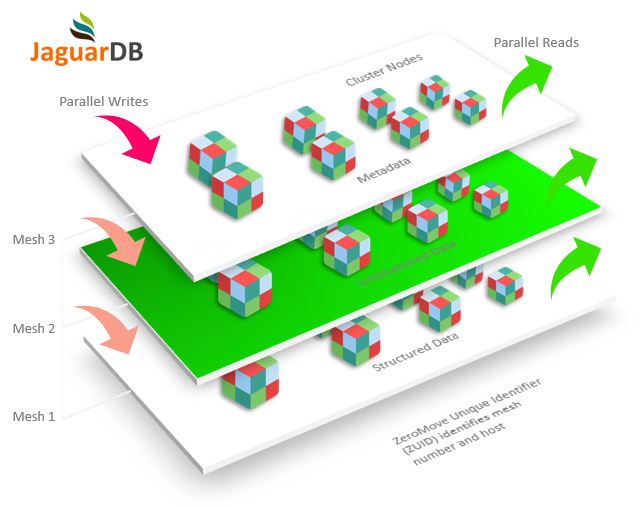
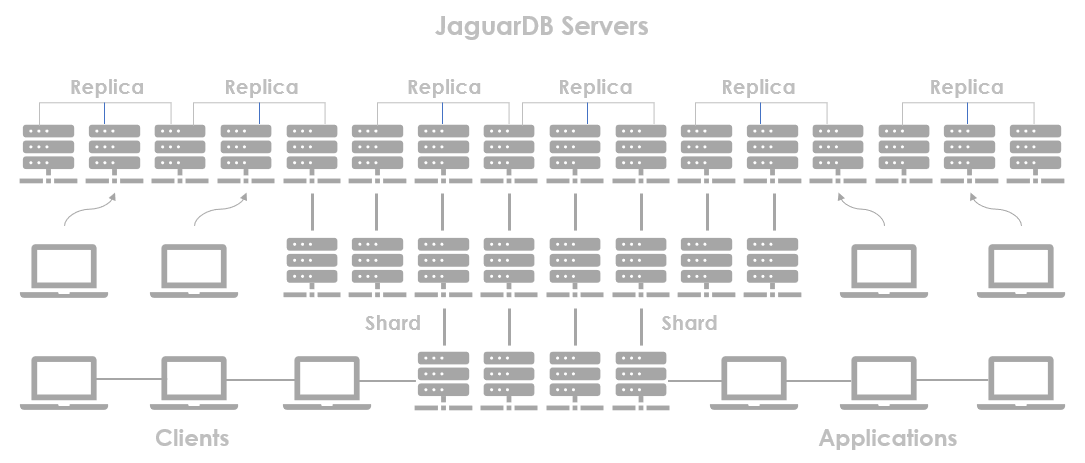
Sharded Multiple Master Architecture
JaguarDB operates using a unique architecture where all nodes in the cluster are master nodes,
capable of both data writes and reads. This approach ensures that write and read bandwidth is
fully utilized, and data is sharded across all nodes to increase both write and read speed.
To ensure high availability and security, data stored on one node is also backed up on two other nodes.
In JaguarDB, geometric shapes are modeled as objects, rather than raw data points with coordinates.
This enables more efficient querying and indexing of spatial data. To achieve high performance,
data reads and writes are distributed across different nodes in the cluster, increasing
concurrency and overall system efficiency.
|
Click here to quickly download JaguarDB software
|