
Vector database sharding
Multimodal search
JaguarDB quantization
JaguarDB Vector API
Best Vector databases
JaguarDB in Docker
Setup JaguarDB with tar package
Setup JaguarDB on multiple nodes
Vector index sharing
How zeromove works
Video introduction
|
|
Guides
Artificial intelligence (AI) often relies on vector databases for various tasks such as natural language processing, information retrieval, recommendation systems, and similarity matching. The use of vector databases is particularly relevant in the context of machine learning models that leverage embeddings, which are numerical representations of data elements in a continuous vector space.
Pods
A Pod serves as a versatile repository designed to house and manage multiple stores within an organization. This structural unit not only functions as a robust database but also excels in promoting streamlined and effective data management. Its primary role lies in facilitating the organized and efficient handling of data, ensuring clear data structures and swift data accessibility.
Stores
A store in JaguarDB bears a resemblance to the tables found in the relational databases, but with the added capability of accommodating multiple vector indexes. This feature grants it with versatility, allowing users to store not just scalar data, but also vector data and raw binary data, making it a multi-purpose storage solution. Multiple stores can exist in a pod.
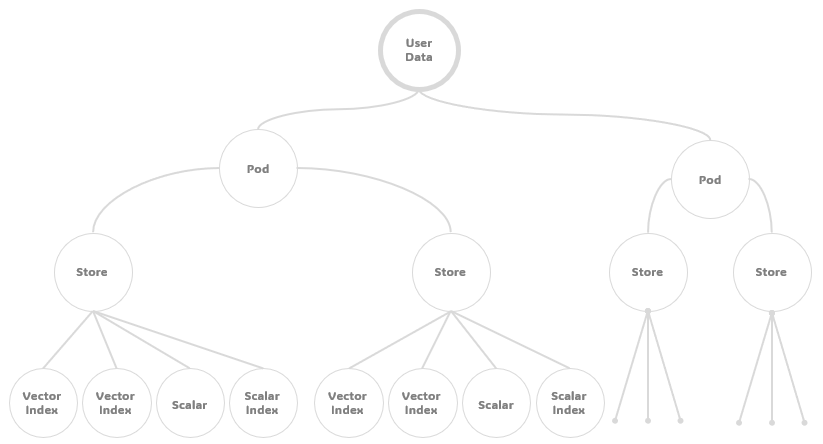
Vector Indexes
A vector index is a data structure or technique used to efficiently store and retrieve high-dimensional vectors.The Hierarchical Navigable Small World (HNSW) is a type of data structure and algorithm used for efficient approximate nearest neighbor search in high-dimensional spaces. It is integrated and extended in JaguarDB to address the challenges of performing nearest neighbor searches in spaces with a large number of dimensions, where traditional search methods become less effective.
Scalar Indexes
A scalar is a table column in database to represent a data attribute. A scalar index is a data structure that improves the speed of scalar data retrieval operations on a database table. It is an integral part of JaguarDB and plays a crucial role in optimizing query performance, on both vector search and scalar search. Scalar indexes together with vector indexes can quickly locate and access data records that satisfy a specific condition.
Efficient Representation
Vectors provide a compact and efficient representation of complex data structures. By transforming data elements into vectors with thousands of dimensions, AI systems can work with numerical representations that are more amenable to mathematical operations and analysis.
Regardless of the complexity or unstructured nature of data, it can be effectively represented by semantic vectors. These vectors are extracted from extensive language models through rigorous training processes. These representations capture the underlying meaning and relationships within the data, allowing for sophisticated analysis, interpretation, and utilization of information. Whether dealing with intricate datasets, textual content, images, or any other form of data, the power of semantic vectors lies in their ability to bridge the gap between raw data and meaningful insights, enabling advanced applications in natural language understanding, data mining, machine learning, and more.
Similarity Metrics
Vector databases enable the computation of similarity or distance metrics between vectors, such as cosine similarity or Euclidean distance. These metrics are fundamental for tasks like similarity matching, nearest neighbor searches, and clustering, which are essential in recommendation systems, content retrieval, and data exploration.
select similarity(vec, 'say you, say me, say it for always','topk=100, type=cosine_fraction_float' )
from vector
where vector.year='80' and vector.lang='english'
Information Retrieval
Vector databases allow AI systems to index and retrieve relevant information efficiently. By converting textual or multimedia content into vectors, it becomes possible to organize and search through large volumes of data quickly. For instance, in a search engine, a vector representation of documents enables fast retrieval of relevant documents based on user queries.
AI Inference
AI inference, in the context of artificial intelligence, refers to the process where a trained machine learning model applies its learned knowledge to make predictions, decisions, or classifications based on input data. During inference, the model takes in new or unseen data and produces an output or inference without further training. This phase is crucial for real-world applications of AI, such as natural language processing, computer vision, and recommendation systems, where the model's ability to make accurate and timely decisions is essential. Inference typically occurs after the model has been trained on a large dataset and deployed to perform specific tasks, enabling it to provide valuable insights, automate processes, and enhance decision-making in various domains.
Semantic Understanding
Vector representations can capture semantic relationships between words or concepts. Techniques like word embeddings (e.g., Word2Vec or GloVe) map words into vectors, where similar words are located closer in the vector space. This enables AI models to understand the context, meaning, and semantic relationships between words, which is vital for natural language understanding and generation tasks.
select anomalous(vec, 'An outlier Einstein is','topk=100,type=cosine_fraction_float')
from vector
Fine-Tuning
Fine-tuning in AI refers to the process of taking a pre-trained machine learning model, often on a large and general dataset, and further optimizing it for a specific task or domain. During fine-tuning, the model's parameters are adjusted using a smaller, task-specific dataset that contains labeled examples relevant to the target application. This process helps the model adapt its learned features and knowledge to perform effectively on a specialized task, improving its accuracy and relevance. Fine-tuning is a valuable technique for transferring knowledge from general AI models to specific applications, saving computational resources and time while achieving robust and tailored performance in various fields like natural language processing, computer vision, and more. The cost and difficulty of fine-tuning a machine learning model can vary significantly based on several factors, including the complexity of the model, the size of the target dataset, the specificity of the task, and the available computational resources.
Why Jaguar
The innovative ZeroMove technique is employed in Jaguar that offers a revolutionary solution. In contrast to the consistent hashing algorithm, which requires data migration when scaling out the system, ZeroMove enables scaling without the need to move data between computers. Data is intelligently tagged with encoded identifiers to facilitate efficient host location. These encoded identifiers serve as unique markers that enable swift and accurate retrieval of data within the system. Our approach ensures that data remains in the host where it is hashed, thereby increasing availability, and improving system performance.
Guidelines
JaguarDB is a robust and versatile data platform designed for AI applications, capable of addressing real-world challenges stemming from diverse data sources and formats. To embark on your JaguarDB journey, the initial step involves crafting a well-thought-out vector store structure. This includes decisions about which data fields to capture and manage, the selection of suitable similarity metrics, considerations regarding data input types, and assessments regarding whether vector data compression is warranted, given memory cost considerations. The design phase necessitates meticulous planning and optimization to ensure an efficient foundation. Once this optimized structure is in place, the subsequent tasks of data ingestion and AI analytics become relatively straightforward, enabling you to harness the full potential of JaguarDB for your AI-driven endeavors.
|